Abstract
Interactive 3D simulated objects are crucial in AR/VR, animations, and robotics, serving as the foundational elements that drive immersive experiences and advanced automation. However, creating these interactable objects (i.e., articulation) requires extensive human effort and expertise, limiting their broader applications. To overcome this challenge, we present Articulate-Anything, a system that automates the articulation of diverse, complex objects from different input modalities, including text, images, and videos. Articulate-Anything leverages Vision-Language Models (VLMs) to generate Python programs compilable into articulated Unified Robot Description Format (URDF) files. Our system consists of a mesh retrieval mechanism and dual actor-critic closed-loop systems. The agentic system is capable of automatically generating articulation, inspecting simulated predictions against ground-truths, and self-correcting errors. Qualitative evaluations demonstrate Articulate-Anything's capability to articulate complex and even ambiguous object affordances by leveraging rich grounded inputs. In extensive quantitative experiments on the standard PartNet-Mobility dataset, Articulate-Anything substantially outperforms prior work in automatic articulation, increasing the success rate from 8.7-12.2% to 75%, setting a new bar for state-of-art performance. Lastly, to showcase an application, we train multiple robotic policies using generated assets, demonstrating the utility of articulation for finer-grained manipulation beyond pick and place.
Overview
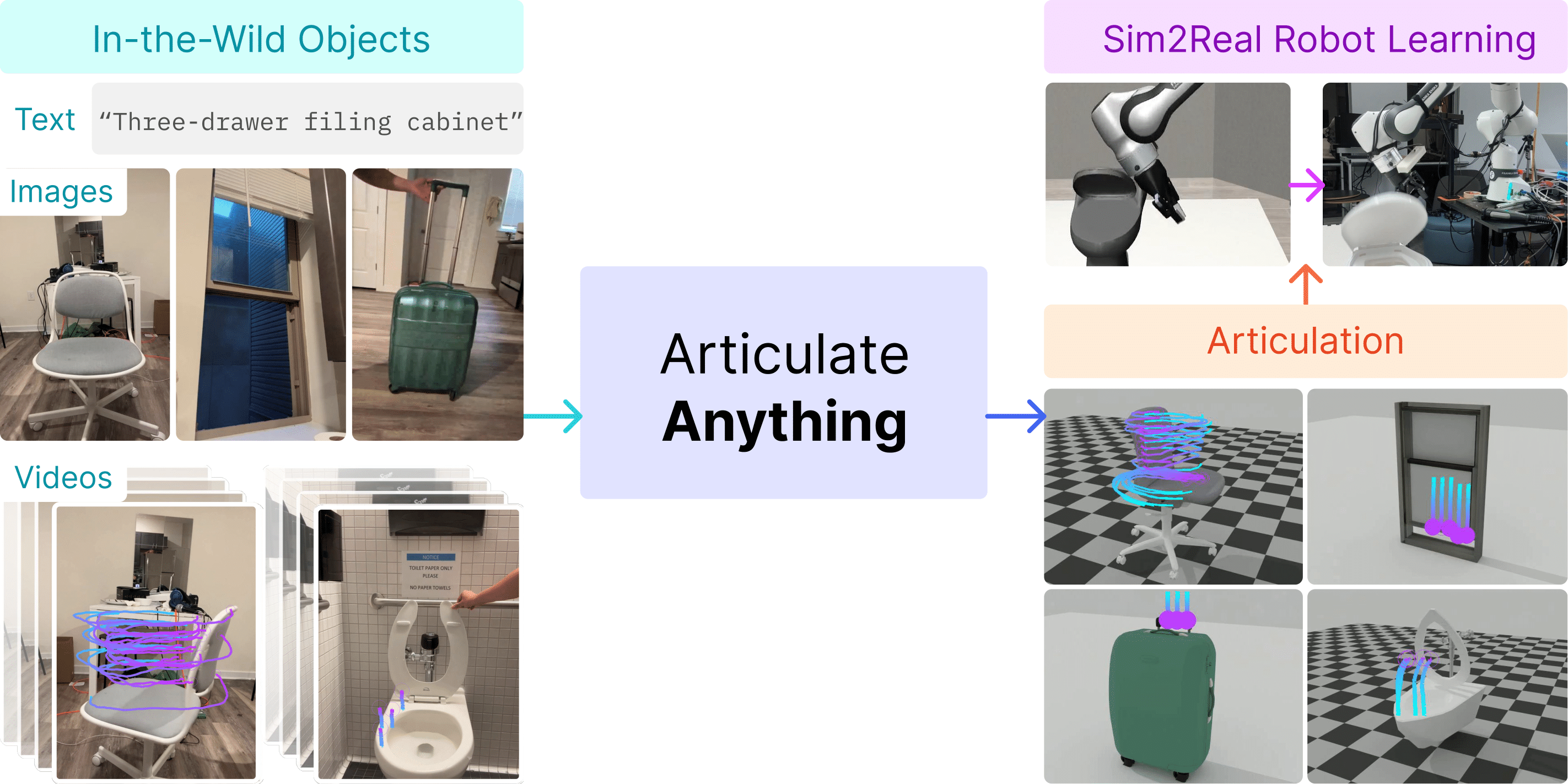
Articulate-Anything is a state-of-the-art method for articulating
diverse
in-the-wild objects from diverse input modalities, including
text, images, and videos. We can create high-quality digital twins in simulation that can be
used to
train robotic skills among
other applications in VR/AR and animation.
Listen to a podcast-style audio description of our work (generated using NotebookLM)!
Listen to a high-level overview of Articulate-Anything.
Method
Articulate-Anything uses a series of specialized VLM systems to automatically generate digital twins from any human-API inputs: text, images or videos.
See a walk-through of Articulate-Anything's system with AI voice from neets.ai.
In-the-wild reconstructions
In this demo, we visualize the articulation results for in-the-wild videos. These videos were
casually
captured on an iPhone (e.g., titled angles) in cluttered environments, showing Articulate-Anything's ability to handle
diverse, complex, and realistic object affordances.
Note that Articulate-Anything can resolve ambiguous affordance by
leveraging grounded
video inputs. For example, double-hung windows can potentially either slide or tip to open. This
affordance is not clear
from static image. When Articulate-Anything is shown a demonstration video, it
can accurately produce
the desired model in simulation.
Below, we show the Python output generated by our system and the corresponding digital twin rendered in Sapien simulator.
![<b>Toilet</b>, articulate-anything:
[sep]
assets/articulation/lab_toilet/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_lab_toilet.webp)
![<b>Oven</b>, articulate-anything:
[sep]
assets/articulation/oven/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_oven.webp)
![<b>Chair</b>, articulate-anything:
[sep]
assets/articulation/chair/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_chair.webp)
![<b>Drawer</b>, articulate-anything:
[sep]
assets/articulation/simple_drawer/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_simple_drawer.webp)
![<b>Suitcase</b>, articulate-anything:
[sep]
assets/articulation/suitcase/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_suitcase.webp)
![<b>Window</b>, articulate-anything:
[sep]
assets/articulation/window/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_window.webp)
![<b>Laptop</b>, articulate-anything:
[sep]
assets/articulation/laptop/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_laptop.webp)
![<b>Display</b>, articulate-anything:
[sep]
assets/articulation/monitor/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_monitor.webp)
![<b>Microwave</b>, articulate-anything:
[sep]
assets/articulation/microwave/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_microwave.webp)
![<b>Box</b>, articulate-anything:
[sep]
assets/articulation/box/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_box.webp)
![<b>Dishwasher</b>, articulate-anything:
[sep]
assets/articulation/dishwasher/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_dishwasher.webp)
![<b>Fridge</b>, articulate-anything:
[sep]
assets/articulation/fridge/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_fridge.webp)
![<b>Kitchen pot</b>, articulate-anything:
[sep]
assets/articulation/kitchen_pot/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_kitchen_pot.webp)
![<b>Door</b>, articulate-anything:
[sep]
assets/articulation/door/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_door.webp)
![<b>Washing machine</b>, articulate-anything:
[sep]
assets/articulation/washing_machine/joint_pred.txt](datasets/in-the-wild-dataset/inputs/resize_aug_washing_machine.webp)
Articulate-anything response shown within code block.Robotics Application
Without articulation, objects can only afford trivial interaction such as pick and place. We show that articulate Articulate-Anything's output can be used to create digital twins in simulation for robotic training of finer-grained manipulation skills, from closing a toilet lid to closing a cabinet drawer. These skills can be then transferred to a real-world robotic system in a zeroshot manner. Here, we visualize the policies trained using PPO in a simulator using Robosuite library for 2 million episodes over 3 random seeds per task.
We execute the best trained policies on a Franka Emika Panda robot arm and show the results below. Note that all training is done in parallel using GPUs in the simulation.
Closing a toilet lid.
Closing a laptop.
Closing a microwave.
Closing a cabinet drawer.
Mesh Generation
Currently, Articulate-Anything employs a mesh retrieval mechanism to exploit existing 3D datasets. Open repositories such as Objaverse contain more than 10 million static objects. Our system can potentially bring those objects to life via articulation. However, as stated, a promising future direction to enable the generation of even more customized assets is to leverage large-scale mesh generation models. Below, we show a few examples of meshes generated by Rodin using in-the-wild images. The static meshes are then articulated by Articulate-Anything.
Quantitative Results
Prior works such as URDFormer and Real2code rely on impoverished inputs such as cropped images or text
bounding box coordinates. Impoverished inputs also mean that their articulation had to be done on an open
loop.
On the standard PartNet-Mobility dataset, Articulate-Anything, leveraging
grounded video inputs and closed-loop actor-critic system,
substantially outperforms these prior works in automatic articulation, setting a new bar
in
state-of-the-art performance.
Articulate-Anything has substantially higher joint prediction success rate compared to other baselines.
In an ablation experiment, we found that indeed richer and more grounded modalities such as videos enable higher articulation accuracy in our own system.
More grounded visual inputs such as images or videos improve accuracies in all articulation tasks.
We also evaluate the effect of in-context examples on success rates for link placement and joint prediction tasks. The results show that providing more in-context examples significantly improves performance.
Success rate vs. number of in-context examples for Link Placement.
Success rate vs. number of in-context examples for Joint Prediction.
Finally, by leveraging a visual critic, Articulate-Anything can self-evaluate its predictions and self-improve over subsequent iterations.
Articulate-Anything can automatically refine and improve its predictions over subsequent iterations.
BibTeX
If you find this work useful, please consider citing:@article{le2024articulate,
title={Articulate-Anything: Automatic Modeling of Articulated Objects via a Vision-Language Foundation Model},
author={Le, Long and Xie, Jason and Liang, William and Wang, Hung-Ju and Yang, Yue and Ma, Yecheng Jason and Vedder, Kyle and Krishna, Arjun and Jayaraman, Dinesh and Eaton, Eric},
journal={arXiv preprint arXiv:2410.13882},
year={2024}
}